WARNING: Below post contains vulgar and potentially offensive language
I have been wanting to learn more about webscraping and working with text data in R, so I thought a great way to do this would be through visualizing data from the online space where I spend a significant amount of time on Sundays during football season: the Green Bay Packers subreddit. During each game of the season, there is a “game thread” where anonymous users post comments about the game as the game is happening (see here for last week’s game thread).
Luckily, there is an R package called RedditExtractoR that can help us scrape comments from Reddit. Along with this package, we will also load the tidyverse package.
library(tidyverse)
## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
## ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
## ✓ tibble 3.1.5 ✓ dplyr 1.0.7
## ✓ tidyr 1.1.4 ✓ stringr 1.4.0
## ✓ readr 2.0.0 ✓ forcats 0.5.1
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
library(RedditExtractoR)
Rather than manually collecting all of the URLs from each of the game threads, I will use the find_thread_urls function to search for threads that contain the phrase “Game Thread: Green Bay Packers vs”, as the title of all game threads contain this phrase.
post_urls <- find_thread_urls(keywords = 'Game Thread: Green Bay Packers vs',
subreddit = 'GreenBayPackers', period = "year")
We can then take a look at the titles of the post that the function pulled for us:
head(post_urls$title)
## [1] "2021 OTAs: May 25th"
## [2] "[Silver] The @packers are trying to negotiate a restructured contract with Aaron Rodgers that could free up cap space... the deal (if it happens) might also inform us about how they view his future in Green Bay. @nflnetwork @PatrickClaybon"
## [3] "Green Bay Packers stock sale tops $36 million, 110,000 shares sold in first two days"
## [4] "[Bukowski] @RapSheet said on @PatMcAfeeShow's show the #Packers wanted to convert Aaron Rodgers' base into signing bonus. Rodgers wanted an extension. Neither happened, so Green Bay moved money w/ other guys."
## [5] "Reasons to be Optimistic about the Postseason"
## [6] "2021 Training Camp: July 29th"
As you can see, something clearly went wrong when searching for just threads that contained the specified keyword, so we will have to clean up this data ourself. Luckily, tidyverse gives us the tools to do this in a few lines of code!
The below code does the following:
-
Renames the column date_utc to just date, and pulls out only the date, title, and url of each post
-
Changes the date column from a character to a date class
-
Selects threads that only happened this season (which started on 9/12/21)
-
Using regular expressions, I select threads that have the phrase “Week [1-18]” somewhere in the title (this is common amongst all game threads). I noticed that the week 4 thread had “Week[4]” so I had to account for the lack of a space between Week and the first bracket.
-
Remove pre-and-post game threads (threads that people comment on before or after the games)
-
Pull out the URLs for all of the game threads
game_thread_urls <-
post_urls %>%
select(date = date_utc, title, url) %>% #rename date_utc to date
mutate(date = as.Date(date, format = "%Y-%m-%d")) %>% # format date column
filter(date > "2021-09-11") %>% # Only select games from 2021 season
filter(str_detect(title, regex("\\[Week.*[(\\d+)]"))) %>% # Select threads with [Week 1-18] in name
filter(!str_detect(title, regex("Pre"))) %>% # Remove pre-game threads
filter(!str_detect(title, regex("Post"))) %>% # Remove post-game threads
pull(url)
We can then use the get_thread_content to get a data frame with comments for the game threads. Due to the reddit API, unfortunately we do not get all of the comments in each thread, but we still get close to 500 for each thread.
game_thread_comments <- get_thread_content(game_thread_urls)[[2]]
We can take a look at the first several comments
head(game_thread_comments$comment)
## [1] "Packers fan here. I'm not going to brag. Chicago may have lost, but the looked good doing it. Also, GB got hoes out of a TD and a pick."
## [2] "Well, at least they got hoes."
## [3] "Pat McAfee might orgasm on air talking about Rodgers saying to Bears fans: \034I\031ve owned you all my fucking life! I own you. I still own you!\035"
## [4] "Well get the bears mod to do something about the fuckin rodgers injury voodoo shit going on in there"
## [5] "THE BEARS STILL SUCK! THE BEARS STILL SUCK! THE BEARS STILL SUCK!"
## [6] "You say the bears suck then why does green Bay have to pay off the refes to win?"
What I decided to do in this post is visualize the most common 200 words in a word cloud. To do this, I will use the unnest_tokens and anti_join functions from the tidytext package. The unnest_tokens function “flattens” each comment, so that I have a data frame where each row is a word from a comment. The anti_join function is then used to remove stop words. I then removed the word “game” since this was not interesting to me, and I also noticed that there was a weird character to remove. Finally, I removed all numbers from the word list.
library(tidytext)
comments_words <-
game_thread_comments %>%
select(comment) %>%
unnest_tokens(word, comment) %>% # Create data frame where each row is a word
anti_join(stop_words) %>% # Remove stop words
filter(!(word %in% c("game", "à"))) %>% # Remove the word "game" and also weird character
filter(!str_detect(word, regex("(\\d+)"))) # Remove numbers
After creating this data frame, I used the count function to count the number of times each word appears in all of the comments, and I selected the 200 most commonly used words.
### Create data frame where each row is a word and the number of times it appears
### And then select top 200 most commonly used words
comments_words_freq <-
comments_words %>%
count(word, name = "freq") %>%
slice_max(freq, n = 200)
Finally, I used the wordcloud2 package to create the word cloud, using a color pallette corresponding to the Packers green and gold.
library(wordcloud2)
color_palette <- c("#203731", "#FFB612")
wordcloud2(comments_words_freq,
color=rep_len(c(color_palette), nrow(comments_words_freq)),
size = .75)
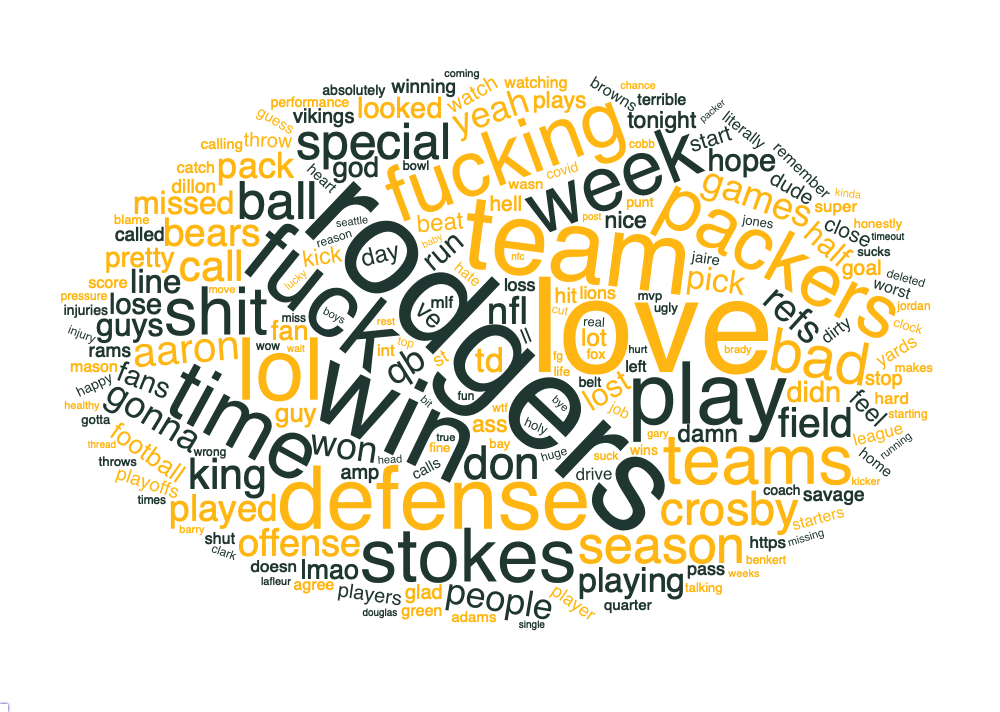
There are some future potential directions to go with this. One would be to dig into the reddit API to get all of the comments, rather than just 500 from each thread. Another would be to train a neural network to generate game thread comments. If you have any ideas, I’d love to hear them!